
Ob Big Data oder Small Data – für jeden Data Scientist stehen am Anfang erst einmal die Daten, welche in eine Form und eine Qualität gebracht werden müssen in der sie sich weiter verarbeiten lassen. Dabei ist es egal ob das Ziel ausgefeilte analytische Methoden oder einfach nur hübsche Visualisierungen sind. Das Motto “Garbage in – Garbage out” gilt nach wie vor, so silicon.de-Blogger Guido Oswald, Sr. Solution Architect bei SAS.
Solange die Datenmengen sehr klein sind, tun ein Texteditor oder Excel ja gute Dienste. Sobald man diese Zone allerdings verlässt wird es schnell sehr (sehr!) mühsam.
Bei der Datenaufbereitung gibt es verschiedene Abstraktions-Layer – je weiter unten desto aufwändiger die Manipulation der Daten:
1. Coding / Programmierung
Die erfahrenen Programmierer unter uns bedienen sich diverser Programmiersprachen um auch mit großen oder sehr großen Datenmengen zu hantieren. Der gute alte SAS Data-Step (bzw. DS2 um innerhalb des Hadoop Clusters massiv parallel zu rechnen), Python oder auch Java tun hier gute Dienste.
Allerdings ist nicht jeder Data Scientist auch gleichzeitig ein erfahrener Programmierer und schreibt täglich Java, Python oder BASE SAS Code. Wer zum Beispiel mit Map/Reduce einfach nur die Worte in einem Text Dokument zählen will muss schon eine Menge tippen: http://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html#Source+Code-N110D1 – ganz schön aufwendig!
2. Höhere Abfragesprachen
Die gute Nachricht ist, das es auch einfacher geht! Wer mit SQL (bzw. HiveQL) zum Ziel kommt kann sehr viel Zeit einsparen. Im Falle von Hadoop kann man mit dem OpenSource Tool Hue schon sehr viel erreichen. Hue ist dabei eigentlich nur eine schicke Oberfläche für eine ganze Reihe von unterliegenden Hadoop Tools wie z.B. Hive, Scoop, dem Metastore, etc.
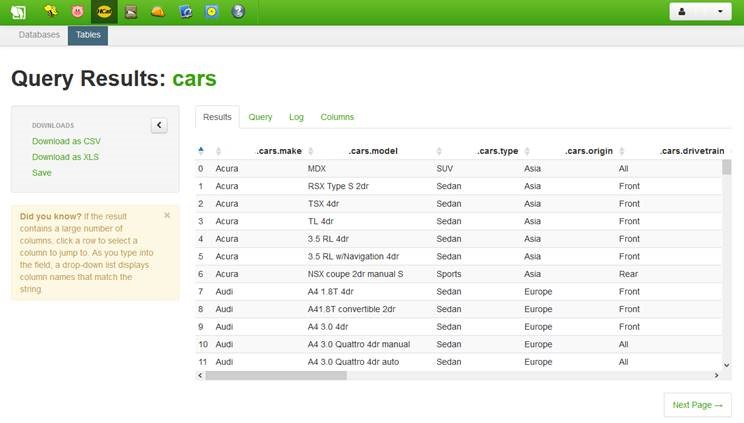
3. UI getriebene Tools (Point & Click Interfaces)
Wer es noch einfacher haben will und auch Datenqualitätsprobleme beheben will, der kann im Zusammenspiel mit Hadoop auch den neuen SAS Data Loader verwenden. Hier hat es viele “Easy Buttons” um die wichtigsten Tasks eines Data Scientisten im Zusammenhang mit der Datenaufbereitung abzudecken:
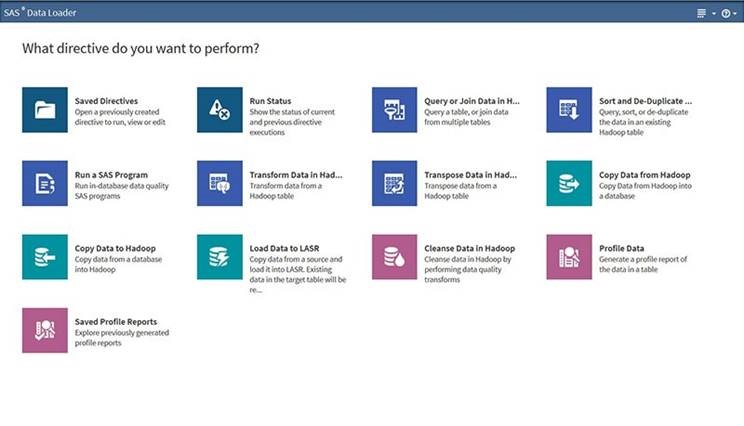
Folgende Aufgaben sollte das Tool der Wahl möglichst effizient abdecken:
- Erste Exploration der Datensätze auf den Quell- und Zielsystemen
- Datenstruktur
- Ausschnitte aus den Daten
- Verschieben auch großer Datenmengen zwischen den Plattformen
- Verbinden mehrerer Tabellen (Append & Join)
- Filtern (Zeilen & Spalten)
- Daten-Profiling (aufspüren von Inkonsistenzen und Datenqualitätsproblemen)
- Datenqualitätsprobleme beheben (z.B. einheitliche Formate, Groß/Kleinschreibung, Adressvalidierung etc.)
- Dubletten finden und filtern
- Daten transponieren
Nach dem Hin-und-her schieben der Daten, dem Zusammenfügen von mehreren Datensätzen, dem Aufräumen und Säubern, kann man das Ergebnis dann in einem Tool der Wahl Explorieren und entweder nochmals durch den Daten-Aufbereitungsprozess iterieren (falls sich weitere Qualitätsprobleme zeigen oder Informationen fehlen) oder weiter zum zweiten Teil der Data Science – der “Science” gehen. Diesen Teil zu beschreiben überlasse ich aber lieber den Experten wie Dr. Diego Kuonen oder meinem Kollegen Carmelo Iantosca. Ich bin ja froh wenn ich Regression fehlerfrei schreiben kann ;)
Am Ende steht dann die Visualisierung. Dabei reichen die Optionen von der Kreuztabelle bis zum animierten Bubble-Chart. Stichwort hier ist “Agile Business Intelligence“.
Mehr Informationen und Anregungen zum Thema Data Science gibt es natürlich auch wieder auf den SAS Foren in der Schweiz (12. Mai) und Deutschland (9. Juni). Einen Persönlichkeitstest zum Thema Data Science gibt es hier: http://www.sas.de/ds.
Weitere Beiträge von SAS zum Thema Data Scientist finden Sie hier.





