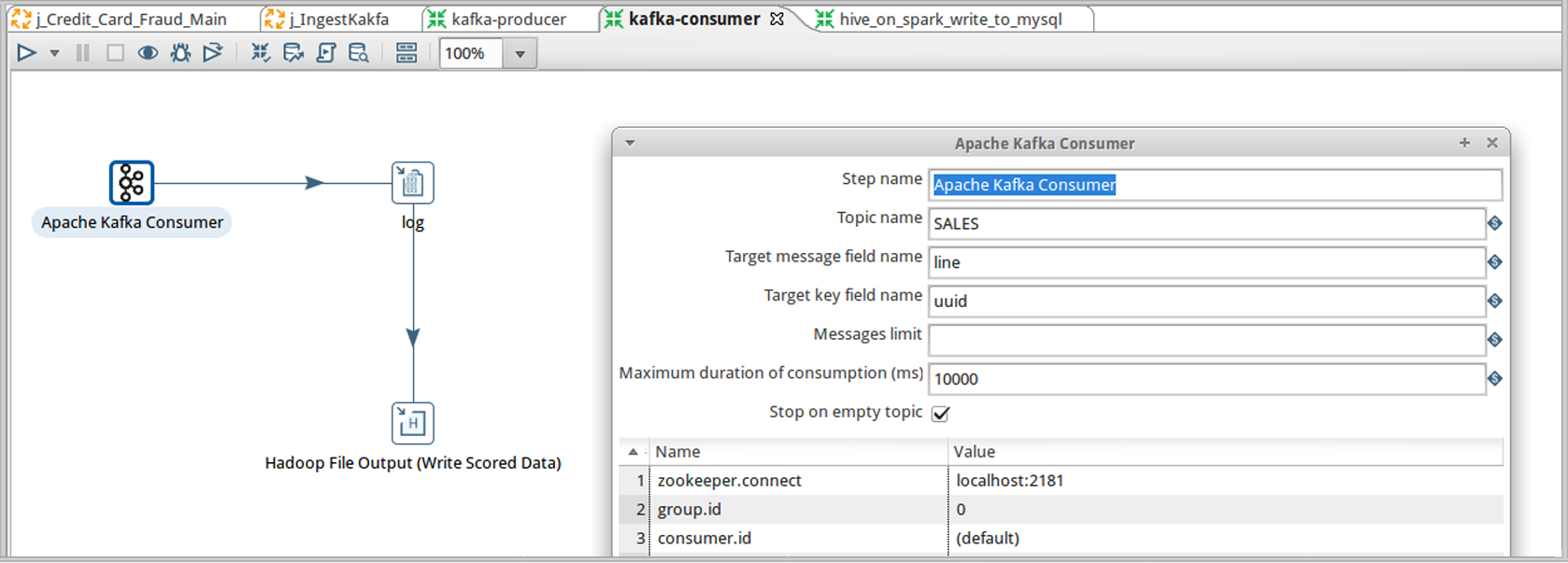
Die Hitachi-Tochter Pentaho stellt die Version 7 der gleichnamigen Business Analytics-Lösung vor. Die ab November erhältliche Version integriert Apache Spark und Kerberos und Sentry und unterstützt nun auch die Hadoop-Formate Avro und Parquet. Pentaho 7 bietet Unternehmen jetzt auch Unterstützung für das Senden und Empfangen von Daten aus Kafka, um durchgehende Datenverarbeitungsanwendungsfälle in Pentaho Data Integration (PDI) zu erleichtern. Das ist vor allem bei IoT- oder Big-Data-Projekten von Vorteil.
Pentaho 7 integriert nun auch Apache Kafka, was vor allem bei der Verarbeitung von IoT-Daten von Vorteil ist. (Bild: Pentaho)
Wichtigste Neuerung aber dürfte aber die Möglichkeit sein, Daten in jeder Stufe der Analyse-Pipeline zu visualisieren. So können Datensätze bereits während des ETL-Prozesses stichprobenartig visualisiert und überprüft werden. Dafür stellt Pentaho 7 ein Frontend bereit. Anwender müssen dann nicht mehr über die wenig intuitiven ETL-Ansichten die Daten überprüfen. Wenn die Datensätze den Erwartungen des Analysten entsprechen, können diese mit einem Klick vollständig in die Ansicht geladen werden. Das beschleunige den Analyse-Prozess und die Anwender müssen nicht mehr zwischen Systemen hin und her wechseln.
Auch sollen so Geschäftsanwender besser mit den Daten umgehen können und auch eigenständig Analysen starten können. Denn nach wie vor seien die Standardprozesse für Datenintegration sehr starr und zeitaufwändig und erforderten die Verwendung vieler unterschiedlicher Tools. Pentaho 7.0 biete IT- und Geschäftsanwendern eine verbesserte Zusammenarbeit bei der Datenvorbereitung, sodass Geschäftsanwender schneller auf die gewünschten Analysen zugreifen können.
Für Apache Spark ermöglicht es Analysten, auch über SQL Spark zu nutzen, um über PDI Daten aus Spark abzufragen und zu verarbeiten. Dank der erweiterten PDI-Orchestrierung für Spark Streaming, Spark SQL und die Technologien für maschinelles Lernen Spark MLlib und Spark ML erlaubt es mehrere Spark-Bibliotheken zu nutzen. Darüber hinaus erlaubt die neue PDI-Orchestrierung auch Spark-Anwendungen auf der Basis von Python.
Dank einer Erweiterung der Pentaho Data Integration (PDI) lässt sich Spark nun auch über SQL nutzen und auswerten. Für Datenanalysten wird es dadurch einfacher, Analysen in Spark zu realisieren. (Bild: Pentaho)
Dank einer neuen Metadaten-Einspeisung lasse sich der Onboarding-Prozess von neuen Datenquellen erleichtern. Dateningenieure können PDI Transformationen jetzt während der Laufzeit dynamisch generieren anstatt diese manuell für jede Datenquelle zu programmieren. Darüber erleichtern 30 weitere PDI-Transofrmationsschritte in Abläufen in Hadoop, Hbase, JSON, XML, Vertica, Greenplum die Einspeisung von Metadaten. Pentaho unterstützt dafür auch die Ausgabe von Dateien in Avro- und Parquet-Formaten in PDI. Beide Formate werden häufig für die Datenspeicherung in Hadoop bei Onboarding-Anwendungsfällen genutzt.
Mit der Erweiterung der bestehenden Integration von Datensicherheitsanwendungen für Hadoop für verbesserte Big Data Governance sollen unautorisierte Zugriffe auf Cluster verhindert werden. Neu ist eine erweiterte Kerberos-Integration für eine sichere Authentifizierung in Multi-User-Umgebungen und eine Apache Sentry-Integration, um Regeln für den Zugriff auf bestimmte Hadoop-Datensätze durchzusetzen.
Im Bereich IoT gibt es zahlreiche Initiativen und Konsortien, bislang laufen diese Bestrebungen jedoch überwiegend parallel nebeneinander her. Doch damit dies alles überhaupt funktionieren kann, braucht man neben neuen Produkten auch neue Standards – insbesondere für die Kommunikation der Geräte untereinander und für die Sicherheit. silicon.de gibt einen Überblick.
{kind=link}
{kind=link}
{kind=link}