Build 2015: Microsoft startet Azure Data Lake
Microsoft treibt die Entwicklung von Big-Data auf der Cloud-Infrastruktur Azure weiter voran und ermöglicht jetzt auch die Speicherung von und Analyse von großen un- oder polystrukturierten Daten. Neben einem Azure Datamart liefert Microsoft auch ein Hadoop-basiertes Filesystem für Data Lakes.
Auf der Entwicklerkonferenz Build stellt Microsoft neue Speichertechnologien auf Basis von Azure vor. Ab heute ist als Preview die “Elastic Database” verfügbar. Mit dieser Erweiterung von Azure SQL Database, können Anwender Pools von Daten erstellen, in denen Datenbanken mit unvorhersehbaren Kapazitätsanforderungen zusammengefasst werden.
So können Entwickler oder ISVs elastische Ressourcen für Hunderte oder Tausende Datenbanken bereitstellen und damit Spitzenlasten abfangen. Neben der Plattform selbst liefert Microsoft auch Tools, über die Abfragen über diese Datenbanken hinweg gefahren werden können. Zudem liefert Microsoft eine zentrale Policy-Verwaltung für diese Pools. Neben neuen Sicherheitsfeatures wie Row-level-Security und Dynamic DataMasking, verbessert Microsoft auch die Volltextsuche der Azure-SQL-Datenbank.
Das Azure SQL Data Warehouse soll als Preview im Verlauf des Jahres verfügbar werden. Mit dieser neuen Option für Azure will Microsoft den Steigenden Bedarf nach elastischen Data-Warehousing-Lösungen in der Cloud begegnen. Anwender können damit bedarfsgerecht auch einzelne Queries abrechnen.
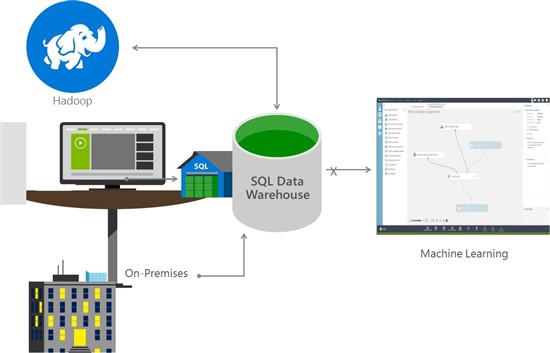
Das Azure SQL Data Warehouse basiert auf der Massively Parallel Processing Architektur, die derzeit auch SQL Server der Analytics Platform System Appliance zugrunde liegen. Unterstützt werden Tools wie Power BI für die Datenvisualisierung, Azure Machine Learning für Advanced Analytics, Azure Data Factory für die Daten Orchestrierung und der Hadoop-verwaltete Bid-Data-Service Azure HDInsight.
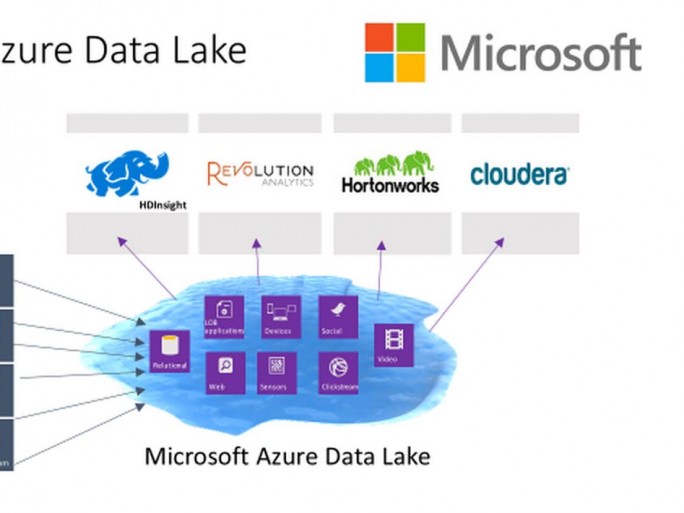
Dem Konzept des Data-Lakes kommt Microsoft mit dem Azure Data Lake entgegen. Dieses Hyper-Scale-Data-Store für umfassende analytische Workloads soll die Begrenzungen traditioneller Analytic-Infrastrukturen auflösen. Die Idee ist es, sämtliche Daten in ihrem nativen Format in einen “See” strömen zu lassen.
Verschiedene Anwendungen können dann einfach auf dieses Zentrale Datenreservoire zugreifen. Dafür ist natürlich ein durchsatzstarker Speicher nötig. Azure Data Lake ist ein auf Hadoop basierendes Datei System, das auch mit HDFS kompatibel ist. Zudem bietet Azure Data Lake eine Integration mit Azure HDInsight. Künftig sollen auch Revolutio-R Enterprise, Clouder oder Hortonworks unterstützt werden. Der Preview soll im Laufe des Jahres verfügbar werden.

“In der Industrie ist das Konzept des Data-Lakes vergleichsweise neu. Es ist ein unternehmensweites Repository, in dem an einem Ort alle Arten von Daten gesammelt werden, ohne formale Unterscheidung und ungeachtet der Größe, Struktur oder wie schnell es eingespielt wird”, erklärt Oliver Chiu, Produkt Marketing für Hadoop und Big Data bei Microsoft. So liefert beispielsweise EMC mit den der aktuellen Produkreihe Isilon entsprechende Hardware für Data Lakes.
Mit dem Datei-Systeme Azure Data Lake sollen Anwender dann in der Lage sein, über Hadoop oder andere analytischen Werkzeuge Muster in dem Datensee zu erkennen. Dieses Konzept brigt einige Vorteile. Chiu erklärt zum Beispiel, dass damit die Daten kostengünstig vorbereitet werden können, bevor diese in ein Data Warehouse geladen werden.
Chiu erklärt weiter: “Es kann große Dateien ohne Größenbegrenzung speichern. Es unterstützt große Mengen von kleinen Speicher-Schritten und dank niedriger Latenzen eignet es sich für Web-Seiten-Analyse, Internet of Things und Analytics in Sensoren und anderen Anwendungen.”




